虽然我们需要的了解 Q* 是什么的关键信息就在眼前,但似乎模因总是比现实更吸引人。
在星期三,就在我们准备放假庆祝感恩节之际,路透社对 OpenAI 进行了最后一次报道,仅透露了 OpenAI 一个新方法 Q* 的名称和一些高层次的评估。这个方法以其模糊而强大的能力被广泛宣传:
路透社联系 OpenAI 后,该公司虽然拒绝发表评论,但在一份内部消息中向员工确认了一个名为 Q* 的项目……
OpenAI 的一些成员认为 Q*(发音为 Q-Star)可能是该公司在追求所谓的人工通用智能(AGI)领域的一个重大突破。OpenAI 将 AGI 定义为在大多数具有经济价值的任务中超越人类的自主系统。
据悉,在庞大的计算资源支持下,这个新模型能够解决特定的数学问题。一位不愿透露姓名的人士表示,尽管该模型在数学方面的表现仅相当于小学生水平,但在这些测试中的出色表现使研究人员对 Q* 的未来充满了期待。
仅凭一个方法的名称就引发了如此广泛的猜测,在以前是闻所未闻的。不过,在这种情况下,名称相对简单,并不仅仅是《沙丘》宇宙中的又一个代号。如果 Q(Q-Star)是真实的,它显然将强化学习(RL)文献中的两个核心概念——Q 值和 A(一个经典的图搜索算法)联系在了一起。有人可能认为 Q 仅指最优策略的价值函数,但这种解释过于荒谬,除非是故意泄露的假消息。考虑到 OpenAI 几乎所有信息都被泄露过,故意制造假消息似乎不太可能。1
我的初步假设,我把它称为一个“锡帽子”理论,是 Q 学习和 A* 搜索的一种模糊结合。我没能回答的问题是,究竟在搜索什么?我最初的猜测是搜索对话转折点,但由于我稍后会提到的基础设施原因,这几乎可以肯定是错误的。
随着我对这个问题的更深入研究,我开始相信他们正在通过树状思维推理在语言/推理步骤中进行搜索,做出了一些有影响力的事情,但这比人们所想象的要小得多。之所以如此夸张,是因为目标在于将大语言模型(LLM)的训练和使用与深度强化学习(Deep RL)的核心部分联系起来,后者使得像 AlphaGo 这样的成功变得可能,核心部分包括自我对弈和提前规划。
自我对弈的概念是指智能体通过与稍有差异的自身版本对弈来提升游戏技能,因为这样可以逐渐遭遇更具挑战性的情况。在大语言模型(LLM)的领域,自我对弈的大部分可能看起来更像是 AI 反馈,而不是竞争过程。
提前规划则是指利用对世界的模型来推理未来,从而产生更好的行动或输出。这两种方法分别基于模型预测控制(MPC)和蒙特卡罗树搜索(MCTS),MPC 通常用于连续状态,而 MCTS 适用于离散动作和状态。
要理解这些如何相互关联,我们需要关注 OpenAI 和其他机构最近发布的研究成果,这些成果将帮助解答两个问题:
- 我们如何构建一个可以进行搜索的语言表征?
- 我们如何构建一个对分割且有意义的语言片段(而非整个完整文本)的价值观?
有了这些答案,我们应该能明白如何使用现有的用于人类和模型反馈强化学习(RLHF)的强化学习方法。我们使用强化学习优化器来微调语言模型,并通过模块化奖励得到更高质量的生成结果(而不是像现在那样针对整个序列)。

DALLE3
使用大语言模型(LLM)的模块化推理:树状思维(ToT)提示
诸如“深呼吸”和“一步步思考”这样的技巧现在正发展成为利用并行计算和启发式算法(搜索的一些基本原理)进行推理的高级方法。
树状思维就像其名字那样直观。它是一种促使语言模型创建可能汇聚于正确答案的推理路径树的方式。论文中展示了使用大语言模型进行问题解决的其他方式与之的比较:
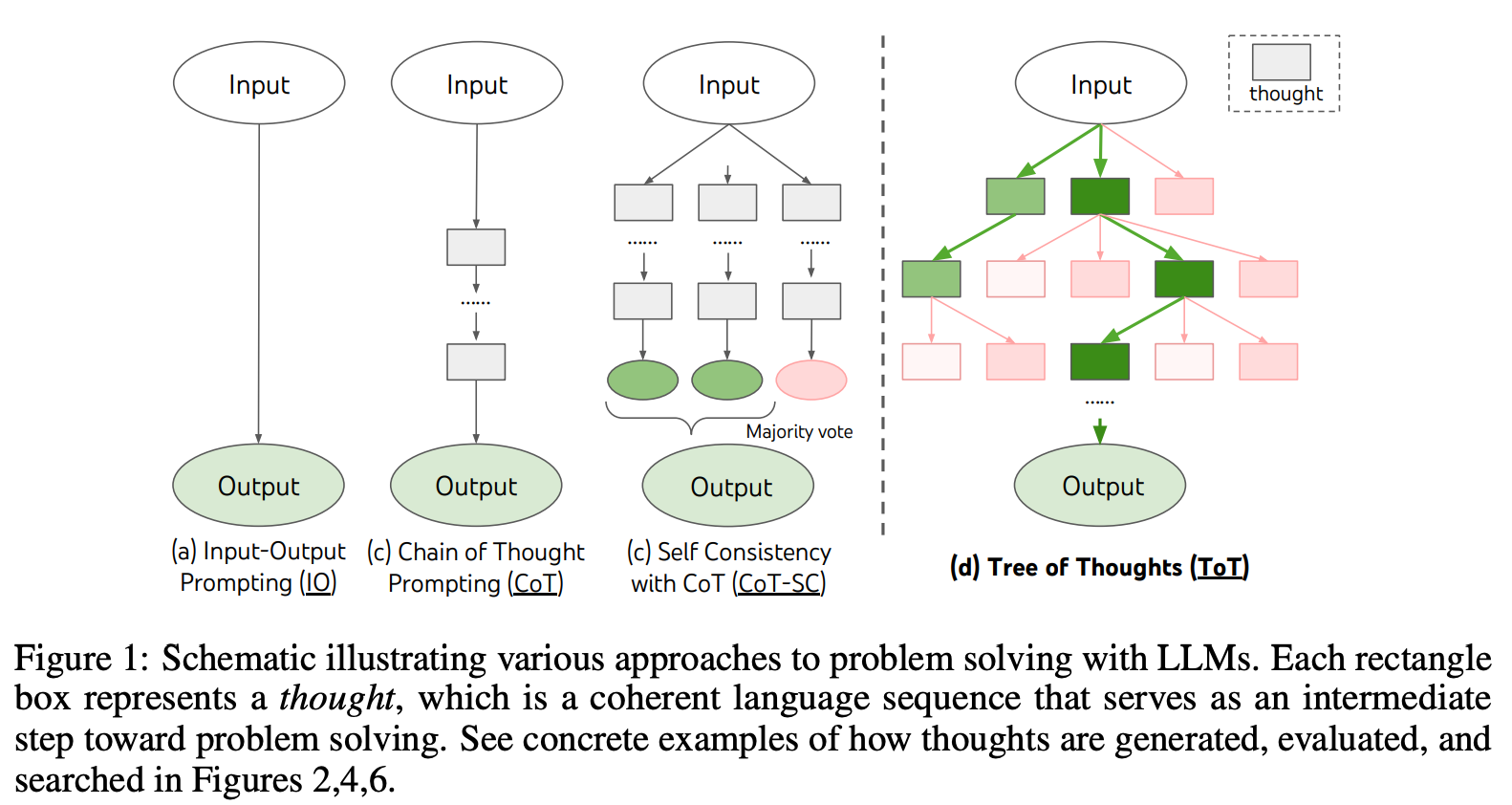
使这种方法有效的创新之处在于对推理步骤的分块和激发模型创造新的推理步骤。ToT 似乎是第一个“递归式”提示技术,用于提高推理性能,这听起来与 AI 安全领域对递归自我改进模型的担忧非常相似(虽然我不是专家)。
利用这些推理树,我们可以应用不同的方法来评分每个顶点(节点)或选择最终路径。这可能基于最短路径到达大多数人同意的答案,或者需要外部反馈的复杂方法,这些方法又将我们引回人类和模型反馈强化学习(RLHF)的方向。
阅读树状思维论文请点击:https://arxiv.org/abs/2305.10601
生成中的细粒度奖励标签:过程奖励模型(PRM)
到目前为止,大多数人类和模型反馈强化学习(RLHF)的做法是对语言模型的整体响应进行评分。对于有强化学习背景的人来说,这是令人失望的,因为它限制了强化学习方法理解文本每个子组件价值的能力。未来可能会涉及到在多个对话轮次上进行多步骤优化,但由于这需要涉及人类或某种提示源,目前这种方法还很遥远。
这种方法可以轻松扩展到自我对弈风格的对话,但给大语言模型(LLM)设定能够转化为持续改进的自我对弈动态的目标却颇具挑战。我们想用大语言模型做的大多数事情都是重复性任务,不像围棋那样有几乎无限的性能提升空间。
另一方面,有一种自然而然将文本划分为包含块的大语言模型使用案例:逐步推理,数学问题是最典型的例子。
过程奖励模型(PRM)是过去六个月我从人类和模型反馈强化学习(RLHF)领域听到最多的话题之一。事实证明,虽然关于这些模型的文献众多,但关于如何将它们与强化学习(RL)结合使用的资料却很少。
PRM 的核心思想是为推理的每一步分配分数,而不是为整个消息打分。OpenAI 的论文《Let’s Verify Step by Step》中的一个示例如下:

还有他们使用的有趣的反馈界面(将被 AI 替代),但这很有启发性:

这使得在解决推理问题时可以进行更精细的生成,通过最大平均奖励或其他指标采样,而不是仅依赖单一分数(在这方面的文献中,标准的 RM 被称为结果 RM)。通过使用最佳-N采样——本质上是多次生成并使用奖励模型得分最高的结果(推理时的拒绝采样法的变种,像 Llama 2 推广的流行方法),PRM 在推理任务上胜过标准 RM。
到目前为止,大部分关于 PRM 的资源仅展示了如何在推理时使用它们。真正的力量将来自于这一信号在训练中的优化。为了创造最丰富的优化环境,能够生成用于评分和学习的多样化推理路径至关重要。这就是树状思维(ToT)的用武之地。ToT 的提示为生成提供了多样性,策略可以学习利用这种多样性,通过访问 PRM。
有关 PRM 的更多资源,请查看以下内容:
- 《Let’s Verify Step by Step》:一篇关于 PRM 的良好介绍。
- 《用过程和结果反馈解决数学应用问题》:2023 年所有 PRM 和推理工作的标准引用。
- 《使用大型语言模型学习数学推理的关系扩展》:一篇研究了拒绝采样方法在推理问题中应用,以及其他贡献的论文。
- 《让我们一步步奖励》:作为推理导航的逐步奖励模型。
此外,还有一个受欢迎的公开可用的数学模型——Wizard-LM-Math,据称是使用 PRM 进行训练的。其次,OpenAI 在今年早些时候发布了《Verify Step by Step》论文中的细粒度奖励标签,用于训练 PRM。